



장르: 애초에 역경을 딛고 이룩하는 숭고한 사랑이란 없다. 그 역경 자체가 사랑이다.
프로그램 특징: 그 곳에서 살아남는 사랑이 어떤 모습으로 걸어오는지 기다려 보고 싶다.
| 데이터 전처리 | 정량 분석 statistics | 정성 분석 visualization | Encoding | Modeling | Feature Analysis | |
| 목적 | 데이터 확인과 데이터 분석이 용이한 형태로 변환 | 통계적 수치를 통해 정보 수집 | 여러 plot 생성 - 유의미한 정보 파악 | 모델링에 적합한 형태로 변환 | 모델의 학습, 성능 확인 ; feature x로부터 Label y 설명 | 어떤 feature X |
| 방법 | 결측치 확인 column의 dtype 및 frequency 분포 확인 | 각 column의 전반적인 통계치 확인, label에 따른 통계치 비교 | Categorical column의 category간 frequency 분포 혹은 Numerical column 간 density 확인 | One-hot encoding, 데이터 값의 범위 및 분포 조절 | Classification; Logistic R, SVM, Random forest | 모델의 coefficient, feature importance score, correlation 분석 -> feature 분석 |
데이터 전처리
데이터 분석 전에, 수집된 데이터를 분석에 용이하게 만드는 과정
- 결측치가 존재하는지 확인하는 게 중요
- Series와 DataFrame, 파일 입출력
- 추가, 삭제, 변환
- 데이터 병합(concat, merge)
- groupby, pivot
Pandas
: 열과 행처리에 적합한 Python 패키지
- SQL Table _ 시계열, 실험 데이터
- 데이터 처리 형태
Series(1차원), DataFrame(2차원)
Series: index로 사용
DataFrame: row와 column으로 구성되고 각 열은 dtype을 가진다.
df.info():
df.head():
정렬(sort)
df.sort_index()
vs. Slicing
indexing은 개별 element를 [ ] 내에 선언해 주어야 가져올 수 있는데 Slicing은 [ : ] 로 가져온다.
- 파이썬은 맨 끝값을 포함하지 않지만 판다스는 포함한다.
df.sort_values(by = ' ', ' ' ), ascending = [ True, False ]
조건 필터링
df.loc[ ]
조건 필터 후 원하는 값을 대입할 수 있다. 단일 컬럼 선택에 유의한다.
- 다중 조건은 condition을 정의하고 &와 ||로 복합 조건을 생성한다.
cond = (df['age'] >= 70)
df.loc[cond]
df.iloc[ ] ; index만 허용하는 loc
df[ 'column_name' ].isin() : 특정 값의 포함 여부
- 파이썬의 in 키워드는 사용 불가하다.
- loc을 활용한 조건 필터링에서도 활용 가능하다.
Excel 불러오기
pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')
dataframe으로 받아올 때 index = true 면 인덱스가 추가되어 저장됨.
> 인덱스가 중첩될 수 있어서 index = False를 많이 이용
CSV 불러오기 / 저장하기
한 파일에 정리가 가능함.
추가 / 삭제 / 변환
추가
- 새로운 칼럼 추가 df['column_name'] = True
- 중간에 칼럼 추가 df.insert(column_index, 'column_name', value):
복사 df.copy() : dataframe
삭제
- df.drop(row_index):
- df.drop('column_name', axis = 1): 열 삭제 시 반드시 axis=1 옵션
- inplace = True - 바로 적용
변환
df1.loc[10, 'age']
칼럼간 연산
df1['round'] = round(df1['fare'] / df1['age'] , 2)
- 연산 시 1개의 열이라도 NaN 값을 포함하고 있다면 결과는 NaN이 됩니다.
colume을 category 타입으로 변환할 수 있습니다. category 타입으로 변환했다면 .cat으로 접근해 category 타입이 제공하는 attribute를 사용할 수 있다.
데이터 결측치
Na, NaN
발생 이유: 데이터에 값이 없는 경우, 데이터의 오류
- concat/merge 등 병합 과정에서 칼럼간 연산 과정에서 등
분석 결과에 영향을 주기 때문에 결측치 대처가 중요합니다.
결측치 처리하는 방법은 다양하며 상황에 맞게 적절한 방식으로 결측치를 찾아 처리하는 것 또한 중요합니다.
- 평균으로 대체하기
- 완전 제거하기
편향 발생할 가능성이 적다. - 회귀 대체법
변수의 특성 적용 가능
1. 결측치 확인 - df.isnull(), df.isna()
- df.isna.sum() - column 별 결측치의 개수 확인
- 결측치가 아닌 데이터 확인 - notnull()
2. 결측치 채우기 - df.fillna(), df['column_name'].fillna()
- column의 평균(mean), 중앙값(median), 최빈값(mode) 등으로 결측치를 채운다.
- 최빈값으로 채울 때에는 반드시 0번째 index 지정해 값을 추출한 후 채워야 한다.
df1['deck'].fillna(df1['deck',mode( )[0]).tail()
결측치 제거 - df.dropna()
- dropna() - NaN이 존재하면 행 제거
- df1.dropna(how = 'all') 로 모든 값이 NaN일 때 행 제거
pandas 데이터 연결
- concat : 두 dataframe을 행(axis=0) /열 방향(axis=1)으로 이어 붙임
ignore_index = True 로 인덱스 통일 - merge : 두 dataframe을 column 이름(key값) 기준으로 이어 붙임
서로 다른 구성의 dataframe도 공통 key값(칼럼)을 가진다면 병합할 수 있다.
how : {left, right, outer, inner(default)}
pandas 특정 column 기준으로 데이터 재구성
- apply() : 더 복잡한 logic의 함수를 칼럼 혹은 dataframe에 적용하고자 할 때 사용
def func(x)
df['who'].apply(func)
df[' '].apply(lambda x: '생존' if x == 1 else '사망') - groupby('column_name').통계func() : 특정 기준으로 데이터 그룹핑
df.groupby('sex').mean()
df.groupby(['sex', 'pclass']).mean()
df.groupby(['sex', 'pclass']) ['survived'].mean()
여기서 조회를 위한 인덱스를 사용하고 싶으면 .index_
여러 통계 함수값 적용 .agg[통계함수1, ... ] - pivot
- crosstab() - column의 frequency table을 생성 > category에서 유용
- df.quantile()
Quantile이란 주어진 데이터를 동등한 확률구간으로 분할하는 지점
df['age'].quantile(0.25_ : Q1보다 작을 확률_ 25%
정량적 데이터 분석(통계 수치)
주로 mean, median, mode를 통해 데이터가 어느 값을 중심으로 뭉쳐있는지 확인
분산, 표준편차, 분위수, Q1(25분위수), Q3(75분위수)를 통해 데이터가 어떤 형태로 퍼져있는지 확인
요약 통계 - describe()
- 기본적으로 Numerical column 통계표
count : 데이터 개수
std : 표준편차 - 문자열 column에 대한 통계표 - describe(include = 'object'))
unique : 고유 데이터의 값 개수
top : 가장 많이 출현한 데이터 개수
freq : 가장 많이 출현한 데이터 빈도수
결측치는 default로 빼고 계산한 값을 보여주고 skipna() = False 하면 NaN로 표기 - outlier가 존재하는 경우, mean()보다 median()을 대표값으로 더 선호한다.
정성적 데이터 분석
데이터 시각화
- scatter plot
- box plot
수치형, subplots()와 함께 사용해 그림 안에 여러 boxplot을 그릴 수 있다.
Matplotlib을 사용하면 pandas보다 자유로운 표현이 가능하다.
- 선형 그래프나 산점도의 경우 marker나 markersize, linestyle, color, alpha(투명도) 등을 설정할 수 있는 것이 장점
plt.plot
- plt.title(" ")
- plt.xlable('x축', fontsize = 20)
- plt.xticks(rotation = )
- plt.legent([' ' , ' ']) // 범례 설정
- plt.xlim() // 축의 끝 값
- plt.plot()
- plt.show()
- plt.savefig('filename', dpi = ) // dpi는 해상도 - 200

추가로, plt.subplot() 과 plt.bar나 plt.barh를 함께 사용해 비교 그래프를 그릴 수 있다.
plt.subplot(행 개수, 열 개수)
- fig, axes[행, 열].plot 형태로 자주 쓴다.
빈도 확인 - Barplot, Barhplot
Pie chart
- explode : 튀어나오는 효과의 비율
- autopct : 퍼센트 표기
데이터 모델링이란?
알고 싶은 값 y에 대해 y 와 x의 관계를 효과적으로 설명하는 f() 함수를 만드는 일
1. 데이터 전처리 및 분석 (정성, 정량)
2. training set과 test set으로 나눈다.
test set으로 모델의 성능을 평가
- 성능평가 과정
모델을 제대로 평가하는 metric(지표)를 사용해야 주어진 데이터에 가장 효과적인 모델을 사용할 수 있다. - regression 평가 방법
MSE
MAE
MSE vs. MAE : 루트 vs. 절댓값 : 후자가 오차에 덜 민감
R-square - Linear Regression
x와 y가 선형의 관계가 있다고 가정했을 때 y_pred가 y와 최대한 가까워지는 y = ax + b의 a, b값을 찾도록 학습 - SVM (Support Vector Machine)
Linear regression과 비슷하지만 "어느 정도의 허용오차 C" 안에 있는 오차값은 허용해 준다. - Random Forest
Decision Tree를 무작위로 여러 개 만든 후, 각 tree마다 나온 decision들을 voting(ensemble)을 통해 최종 y 예측
Decision Tree "해당 기준을 만족/불만족시 y값이 ~값일 것이다."라는 조건 x과 결과 y를 나무처럼 발전시킨다.
Regression에서는 y가 평균값, Classification에서는 y값이 클래스
n_estimators(트리의 개수), max_depth(각 트리의 길이)
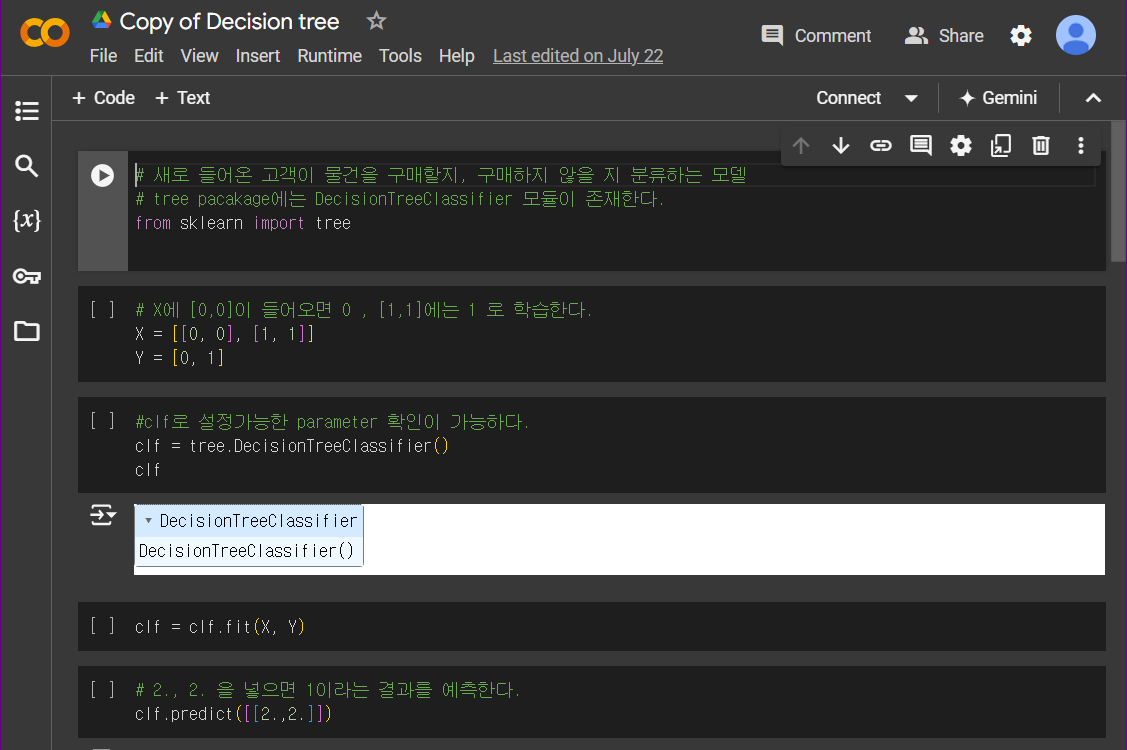

Classification
- Accuracy
- precision & recall
3. inference 과정
귀무가설과 대립가설 설정
가설 내용을 통계적으로 바꾸는 과정
미국 여성의 평균 키는 170cm이다. 는 통계적 가설에 대해서 평균 신장은 모집단 특성을 나타내는 모수가 된다.
통계적 가설은 귀무가설(Null hypothesis, H0)이 이와 반대되는 대립가설(Alternative hypothesis, H1)로 나타낸다.
H0: Mu(평균값) = 170
(1) H1: Mu != 170
(2) H1: Mu < 170
(3) H1: Mu > 170
(1) 은 양측 검정이라 하고 (2), (3)은 단측 검정이라고 한다.
검정 결과 : p-value는 관찰된 데이터가 귀무가설과 양립하는 정도를 [0,1] 수치로 표현한 것
- p-value가 alpha(유의수준)보다 작은 경우 귀무가설이 기각되고, 평균값이 유의미하게 다르거나 크다/작다고 말한다.
- alpha는 보통 0.05, 양측 검정의 경우 0.025이다.
어떤 feature가 결과에 영향을 주는지 파악하는 과정이다.
Regression에서 Linear regression, Classification에서 Logistic regression 은 학습이 된 상태에서 .coef_ 와 .intercept_ 를 조회할 수 있다.
- Attribute는 괄호 없이 입력 - lgr.coef_, lgr.intercept_
- .coef_ : 각 feature에 대해 각각 곱해지는 값 - 절댓값이 상대적으로 큰 feature은 label에 의미가 있다.
- .intercept_ : 각 feature에 대한 절편
Feature analysis
- Linear/ Logistic Regression
label 설명에 중요한 feature인지 확인 가능 (group - 상관관계 분석
상관관계란 통계적 변인과 다른 통계적 변인이 공변 하는 함수 관계
두 상관계수 모두 1/-1에 가까울 수록 양/음의 상관관계가 있다고 이야기할 수 있고, 같이 나오는 p-value의 경우
'H0: 두 변수는 상관관계가 없다.' 라고 하는 가설에 대한 p-value다.
*인과관계가 아니다. - pearsonr()
두 변수 간의 선형 상관관계의 정도 - spearmanr()
두 변수간의 x와 y 크기 순서상의 상관관계 정도 - SVM
Linear와 비슷하므로 학습된 상태에서 .coef_ 와 .intercept_ 를 조회할 수 있다. - Random forest
feature importance score를 자체 제공한다.
rfc.feature_importance
'Data Science' 카테고리의 다른 글
| [Excel] VBA로 데이터 자동화하기 (1) | 2025.03.04 |
|---|---|
| 파이썬 가상환경설정 (0) | 2025.01.07 |
| [파이썬으로 시작하는 데이터 사이언스] 파일 경로 설정 (3) | 2024.08.06 |
| [데이터분석가가반드시알아야할모든것] 10. 데이터 탐색과 시각화 (2) | 2024.07.24 |
| [프로젝트로 배우는 데이터사이언스] 분류모델 기초 1.1 사이킷런과 머신러닝 (3) | 2024.07.22 |