



장르: 애초에 역경을 딛고 이룩하는 숭고한 사랑이란 없다. 그 역경 자체가 사랑이다.
프로그램 특징: 그 곳에서 살아남는 사랑이 어떤 모습으로 걸어오는지 기다려 보고 싶다.
데이터 셋 - 캐글 Bank Customer Churn
무엇이 고객 이탈에 영향을 미치는 지 살펴보고 고객 이탈 유무 판단하기

분류에는 이진 분류와 다중 분류가 있다.
| 이진 분류 | 다중 분류 |
| 레이블 두 개 | 레이블 세 개 이상 |
| 스팸 메일 분류 | 손글씨(0~9)로 분류 |
| 주요 알고리즘 Logistic Regression kNN |
|
| 분류모델 성능평가지표 AUC(Area Under ROC Curve) CA(Classification Accuracy) F1-score MCC |
|
알고리즘
Logistic Regression : 데이터가 어느 범주에 속하는지 [0,1]로 예측
- Regularization
- ridge regression , Lasso regression
- Logistic vs. Linear
Linear regression 의 결과 y에 Sigmoid func를 적용해 y을 [0,1]으로 만든다.
> Classfication에 적합화된 Linear가 Logistic regression이다. - Regression의 SVM과 Random Forest도 Classification에서 사용 가능하다.
- Regression 모델 실습과 분류 모델에서 사용하는 Regression 용어에 어떤 차이가 있는 건지, 어떻게 이해해야 하는 건지 헷갈린다.
분류모델 성능평가 지표
kNN : 가장 가까운 k개의 이웃 데이터를 활용하여 새로운 데이터를 분류하고 예측한다.
- 거리 측정 - Euclidean, Manhattan
- 가까운 이웃을 찾기
- 분류 및 예측을 한다.
AUC
- 실제값 Negative 를 x축으로, Positive를 y축으로 놓는다.
다중공선성 Multicollinearity
feature 간 선형 종속성이 높으면 - 상관계수가 0.7 이상이면 둘 중 하나는 제거해야 모델의 안정성을 유지한다.
//갑자기 딴 길로 새버림..
대검찰청 범죄 발생지 현황_2022 자료를 이용해 feature간 correlation 확인해봐야겠다.
'서울' 키워드가 들어간 feature의 correlation을 살펴보자
Spearman corrlation 과 Pearson correlation이 있다.
- 두 개의 차이는 나중에 찾아보자!
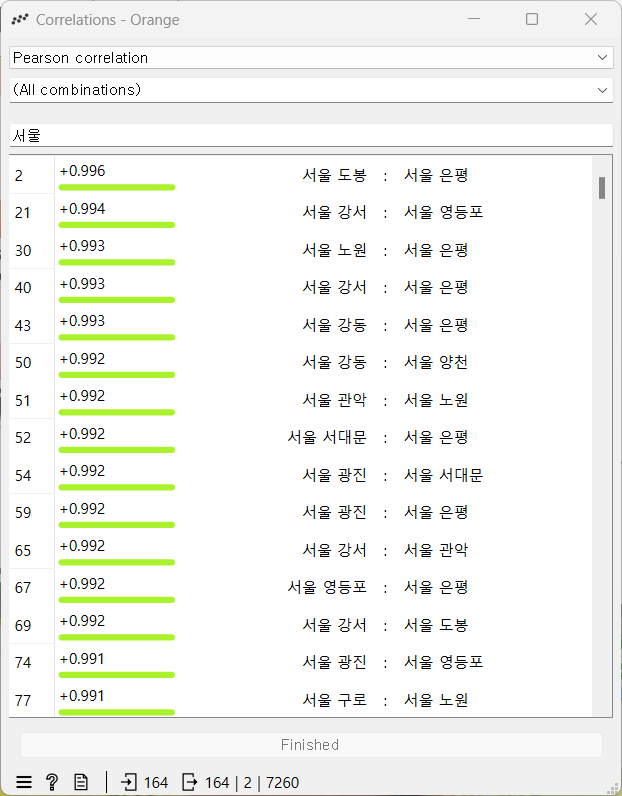

수치 차이가 거의 안나서 정보로 가치는 없어보이지만 그냥 신기했다. (뉴비)
Rank도 확인해보자. 제주를 target 으로 하여 Rank를 확인하고자 한다.
실제로 제주는 지난 2020년부터 3년째 인구 1000명당 범죄 발생 건수 1위의 불명예를 안고 있다.
출처 : https://www.sedaily.com/NewsView/29YIE6CPNP


인천 옹진군이 최하위였다. 어떤 지역인지 옹진군에 한 번 여행가봐야겠다.
데이터 분석 후 데이터 검정으로 데이터 샘플 설정
데이터 분석
Box Plot으로 데이터 분포를 확인한다.

IQR = 3Q - 1Q
이상치는 제거한다.

PCA (Principal Component Analysis)
고차원(feature가 많은)의 x에 대해 주어진 x들의 분포를 가장 잘 설명하는 x, y축을 찾아내는 기술
주로 데이터의 전반적인 분포 visualization에 유용하다 (Scatter Plot)
데이터 검정
Numerical data는 t 검정 : 두 집단의 p = 0.05 보다 크면 평균 차이가 있다고 간주하고 데이터를 제거한다.
Categorical data는 카이 제곱 : p = 0.05 보다 크면 제거한다.
전처리_스케일링
kNN은 거리 기반 데이터 학습 방법이므로 feature 간 범위 차이가 많이 날수록 크게 영향 받아 스케일링 필요하다
Preprocess 으로 범위 간격이 넓은 항목은 Normalize 한다.
- 스케일링하면 정규분포가 치우친 항목의 성능을 높일 수 있으므로 전체 모델에 스케일링한 데이터를 적용한다.
- 예를 들어, 나이를 standard 정규화로 전처리해주었다.
Confusion Matrix
| 예측값 | ||||
| Negative | Positive | |||
| 실제값 | Negative | TN | Type 1error | TN- Specificity 특이도 |
| Positive | Type 2 error | TP | TP- Sensitivity 민감도, Recall 재현율 | |
| TP- Precision 정밀도 | Accuracy 정확도 | |||
Precision vs. Sensitivity(Recall)
실제 positive 중에서 예측한 값이 몇 개나 positive인지 . vs. positive라고 잡은 샘플 중 실제 Positive가 몇 개인지
Type 1 error vs. Type 2 error
False positive가 늘어나는 것이 문제인 경우에는 precision을 높이는 것이 중요하다 - 스팸 메일
False positive가 늘어나도 positive를 잡아내는 것이 중요한 경우 recall을 높이는 것이 중요하다.
- 의료분야 - 실제로 암인데 예측에 negative가 나오는 Type 2 error 를 줄여야 하므로
'Data Science > Machine Learning' 카테고리의 다른 글
| 기계 학습 개요 (8) | 2024.10.17 |
|---|---|
| Linear/Polynomial Regression (2) | 2024.10.13 |
| [금융전략을 위한 머신러닝] NLP (9) | 2024.10.10 |
| 지도 학습: 회귀(시계열 모델) (7) | 2024.09.24 |
| [머신러닝] 오렌지3로 회귀모델 실습하기 (3) | 2024.07.05 |